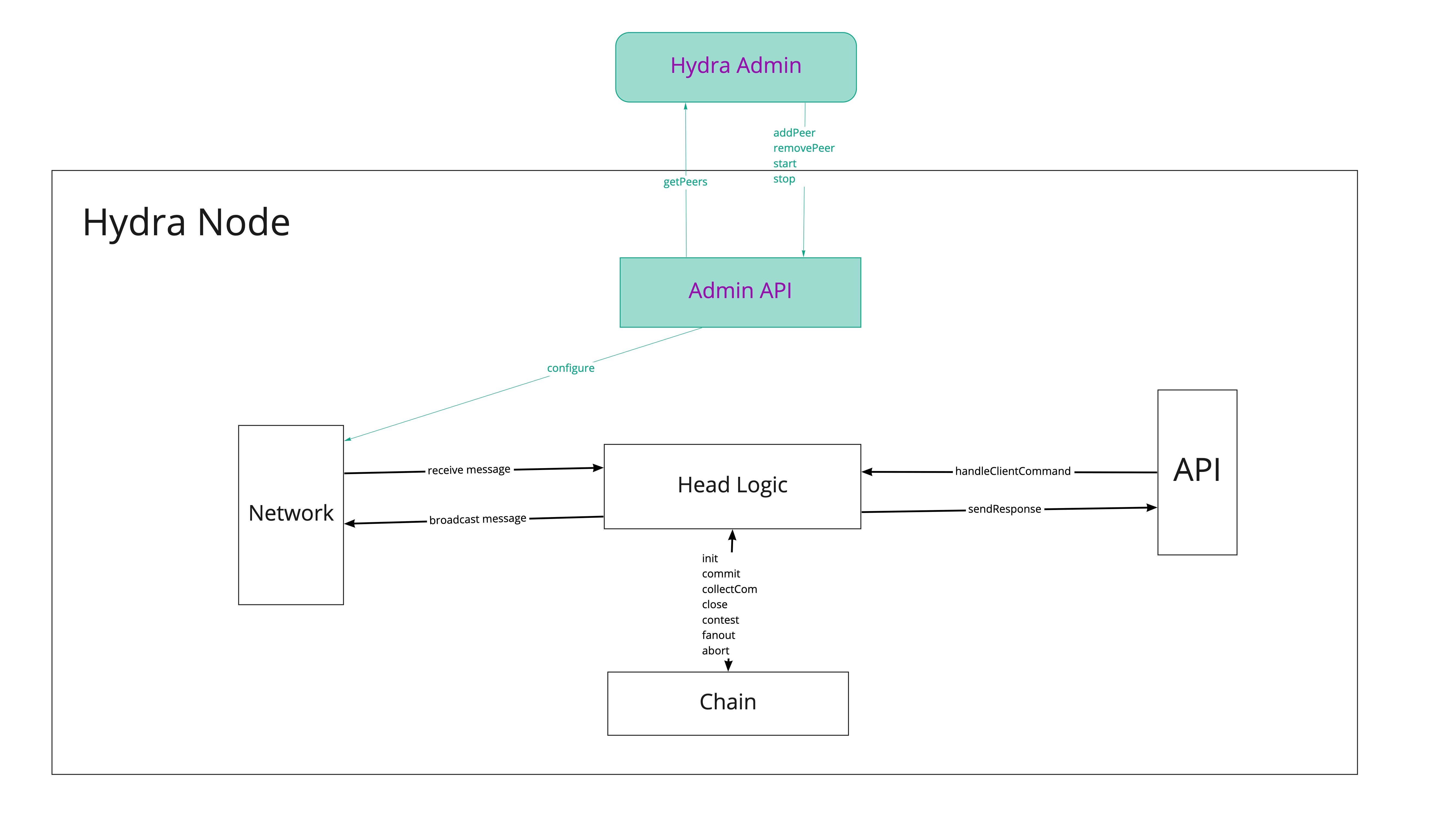
Status
Accepted
Context
- To implement Hydra Head's ledger we have been working with the ledger-specs packages which provide a low-level interface to work with transactions and ledgers
- We also use a lightly wrapped ledger-specs API as our interface for Off-chain transaction submission. This introduced some boilerplate in order to align with cardano-api and provide JSON serialisation.
- In our initial experiments connecting directly to a cardano node we have also been using the ledger API for building transactions for want of some scripts-related features in the cardano-api
- cardano-api is expected to be the supported entrypoint for clients to interact with Cardano chain while ledger-specs is reserved for internal use and direct interactions with ledgers
- cardano-api now provides all the features we need to run our on-chain validators
Decision
Therefore
- Use cardano-api types and functions instead of ledger-specs in
Hydra.Chain.Directcomponent - Use cardano-api types instead of custom ones in
Hydra.Ledger.Cardanocomponent
Consequences
- Removes the boilerplate in
Hydra.Ledger.Cardanorequired to map cardano-api types sent by clients to builtin and ledger-specs types - Simplifies the
Hydra.Chain.Directcomponent:- Replaces custom transaction building in
Tx - Replaces custom transaction fees calculation and balancing in
Wallet - Replace low-level connection establishment using cardano-api functions connecting to the node (keeping the chain sync subscription)
- Replaces custom transaction building in