

15. Configuration Through an Admin API
· 4 min read
Status
Proposed
Context
- Hydra-node currently requires a whole slew of command-line arguments to configure properly its networking layer:
--peerto connect to each peer,--cardano-verification-keyand--hydra-verification-keyto identify the peer on the L1 and L2 respectively. - This poses significant challenges for operating a cluster of Hydra nodes as one needs to know beforehand everything about the cluster, then pass a large number of arguments to some program or docker-compose file, before any node can be started
- This is a pain that's been felt first-hand for benchmarking and testing purpose
- Having static network configuration is probably not sustainable in the long run, even if we don't add any fancy multihead capabilities to the node, as it would make it significantly harder to have automated creation of Heads.
- There's been an attempt at providing a file-based network configuration but this was deemed unconvincing
- Hydra paper (sec. 4, p. 13) explicitly assumes the existence of a setup phase
- This setup is currently left aside, e.g. exchange of keys for setting up multisig and identifying peers. The hydra-node executable is statically configured and those things are assumed to be known beforehand
Decision
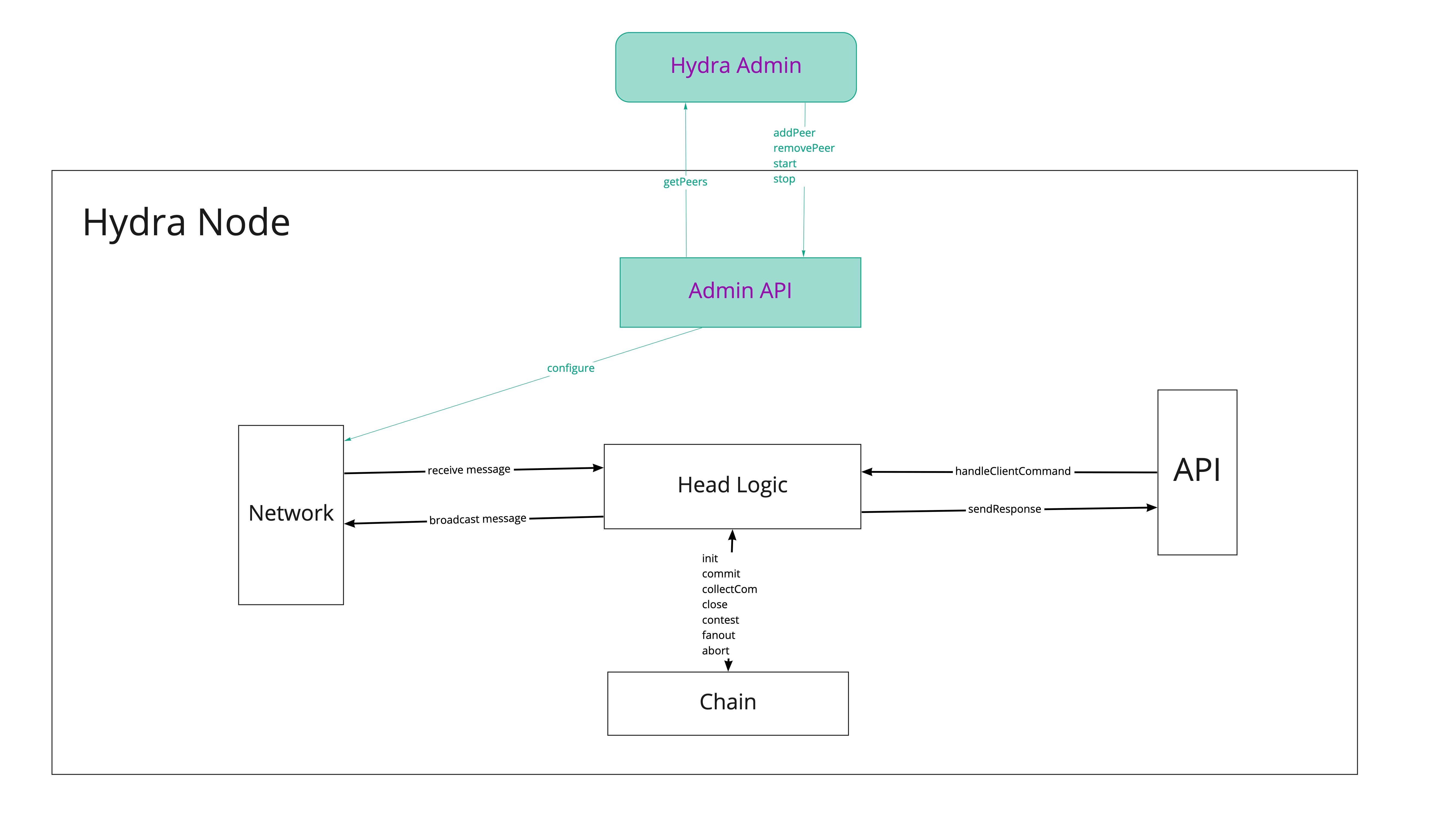
- Hydra-node exposes an Administrative API to enable configuration of the Hydra network using "standard" tools
- API is exposed as a set of HTTP endpoints on some port, consuming and producing JSON data,
- It is documented as part of the User's Guide for Hydra Head
- This API provides commands and queries to:
- Add/remove peers providing their address and keys,
- List currently known peers and their connectivity status,
- Start/stop/reset the Hydra network
- This API is implemented by a new component accessible through a network port separate from current Client API, that configures the
Networkcomponent
The following picture sketches the proposed architectural change:
Q&A
- Why a REST interface?
- This API is an interface over a specific resource controlled by the Hydra node, namely its knowledge of other peers with which new _Head_s can be opened. As such a proper REST interface (not RPC-in-disguise) seems to make sense here, rather than stream/event-based duplex communication channels
- We can easily extend such an API with WebSockets to provide notifications (e.g. peers connectivity, setup events...)
- Why a separate component?
- We could imagine extending the existing APIServer interface with new messages related to this network configuration, however this seems to conflate different responsibilities in a single place: Configuring and managing the Hydra node itself, and configuring, managing, and interacting with the Head itself
- "Physical" separation of endpoints makes it easier to secure a very sensitive part of the node, namely its administration, e.g by ensuring this can only be accessed through a specific network interface, without relying on application level authentication mechanisms
Consequences
- It's easy to deploy Hydra nodes with some standard configuration, then dynamically configure them, thus reducing the hassle of defining and configuring the Hydra network
- It makes it possible to reconfigure a Hydra node with different peers
- The Client API should reflect the state of the network and disable
Initing a head if the network layer is not started- In the long run, it should also have its scope reduced to represent only the possible interactions with a Head, moving things related to network connectivity and setup to the Admin API
- In a Managed Head scenario it would even make sense to have another layer of separation between the API to manage the life-cycle of the Head and the API to make transactions within the Head
- Operational tools could be built easily on top of the API, for command-line or Web-based configuration
