

Networking
This page provides details about the Hydra networking layer, through which hydra nodes exchange off-chain protocol messages. The off-chain protocol relies heavily on the correct operation of the multicast abstraction (broadcast in our fully connected topology here) in the way it is specified and the following sections explain our realization in the Hydra node implementation.
Interface
Within a hydra-node, a Network component provides the capability to reliably broadcast a message to the whole Hydra network. In turn, when a message is received from the network, the NetworkCallback signals this by invoking deliver. This interface follows reliable broadcast terminology of distributed systems literature.
Given the way the off-chain protocol is specified, the broadcast abstraction required from the Network interface is a so-called uniform reliable broadcast with properties:
- Validity: If a correct process p broadcasts a message m, then p eventually delivers m.
- No duplication: No message is delivered more than once.
- No creation: If a process delivers a message m with sender s, then m was previously broadcast by process s.
- Agreement: If a message m is delivered by some correct process, then m is eventually delivered by every correct process.
See also Module 3.3 in Introduction to Reliable and Secure Distributed Programming by Cachin et al, or Self-stabilizing Uniform Reliable Broadcast by Oskar Lundström; or atomic broadcast for an even stronger abstraction.
Fault model
Although the Hydra protocol can only progress when nodes of all participants are online and responsive, the network layer should still provide a certain level of tolerance to crashes, transient connection problems and non-byzantine faults.
Concretely, this means that a fail-recovery distributed systems model (again see Cachin et al) seems to fit these requirements best. This means, that processes may crash and later recover should still be able to participate in the protocol. Processes may forget what they did prior to crashing, but may use stable storage to persist knowledge. Links may fail and are fair-loss, where techniques to improve them to stubborn or perfect links likely will be required.
See also ADR 27 (superseded) and ADR 32 for more context on required properties of the network layer and attempts to achieve fault tolerance.
Topology
Currently, the hydra-node operates in a static, fully connected network topology where each node connects to each other node and a message is broadcast to all nodes. For this, we need to pass publicly reachable endpoints of all other nodes via --peer options to each hydra node and all links must be operational to achieve liveness1.
Future implementations of a the Network interface could improve upon this by enabling mesh topologies where messages are forwarded across links. This would simplify configuration to only need to provide at least one --peer, while peer sharing in such a network could still allow for redundant connections and better fault tolerance.
Authentication
The messages exchanged through the Hydra networking layer between participants are authenticated. Each message is signed using the Hydra signing key of the emitting party, which is identified by the corresponding verification key. When a message with an unknown or incorrect signature is received, it is dropped, and a notification is logged.
Encryption
Currently, communication is not encrypted.
If confidentiality is required, two options exist: encrypt individual messages (symmetric block cipher initiated through a key exchange) or establish encrypted channels between peers (e.g. using TLS).
Implementation
The current implementation of the network stack consists of two components:
Authenticatecomponent that signs all outgoing and verifies incoming messages using the Hydra snapshot key pairEtcdcomponent that re-uses etcd to implement a reliablebroadcastprimitive
See ADR 32 for a rationale of this approach.
Previous network stack
In the past we had a "hand-rolled" network stack to implement reliable broadcast in a fully connected network topology.
- Hydra nodes form a network of pairwise connected peers using point-to-point TCP connections that are expected to remain active at all times
- Using ouroboros-framework to establish point-to-point stream-based connections in a simple
FireForgetprotocol (stateless, just sending messages). - Nodes keep a "valency" matching the number of other peers and broadcast messages to everyone.
- Implement basic failure detection through heartbeats and monitoring exchanged messages.
- Reliable broadcast is (attempted to be) realized by storing outgoing messages, acknowledgments via a vector clock transmitted on each message, and message resending if clock is out-of-sync.
However, it was not as reliable as we hoped (in theory it should have worked) and we pivoted to the current, etcd-based implementation.
Gossip diffusion network (idea)
The following diagram illustrates an ideated pull-based messaging system for Hydra. This would follow the design of the Cardano network stack:
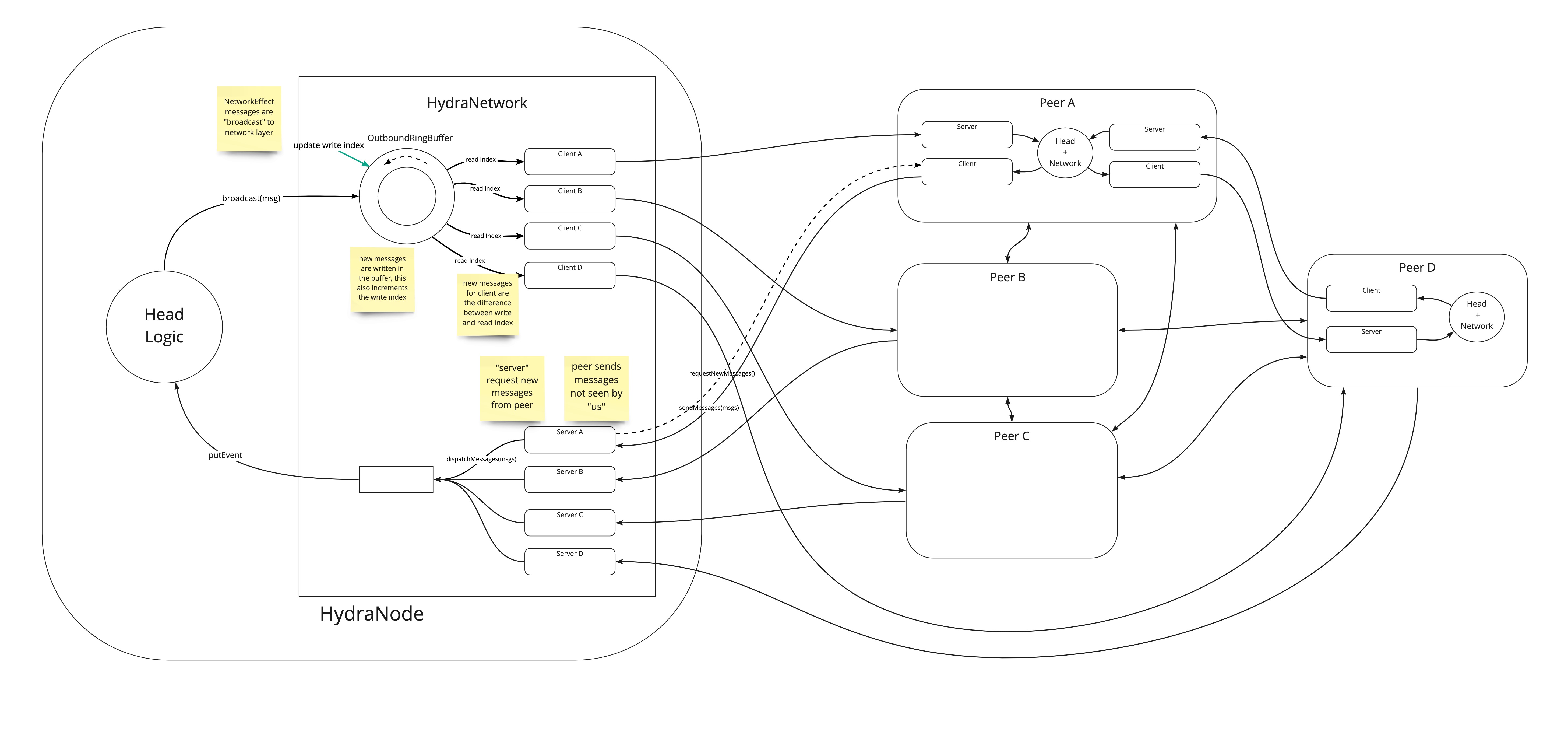
This was not (yet) pursued as it does not fit the broadcast interface as required by the Hydra Head protocol design. However, we think it should be possible to represent the off-chain protocol using pull-based semantics and follow this approach.
Network resilience testing
In August 2024 we added some network resilience tests, implemented as a GitHub action step in network-test.yaml.
The approach is to use Pumba to inject networking faults into a docker-based setup. This is effective, because of the NetEm capability that allows for very powerful manipulation of the networking stack of the containers.
Initially, we have set up percentage-based loss on some very specific
scenarios; namely a three-node setup between Alice, Bob and Carol.
With this setup, we tested the following scenarios:
-
Three nodes, 900 transactions ("scaling=10"):
- 1% packet loss to both peers: ✅ Success
- 2% packet loss to both peers: ✅ Success
- 3% packet loss to both peers: ✅ Success
- 4% packet loss to both peers: ✅ Success
- 5% packet loss to both peers: Sometimes works, sometimes fails
- 10% packet loss to both peers: Sometimes works, sometimes fails
- 20% packet loss to both peers: ❌Failure
-
Three nodes, 4500 transactions ("scaling=50"):
- 1% packet loss to both peers: ✅ Success
- 2% packet loss to both peers: ✅ Success
- 3% packet loss to both peers: ✅ Success
- 4% packet loss to both peers: Sometimes works, sometimes fails
- 5% packet loss to both peers: Sometimes works, sometimes fails
- 10% packet loss to both peers: ❌Failure
- 20% packet loss to both peers: ❌Failure
"Success" here means that all transactions were processed; "Failure" means one or more transactions did not get confirmed by all participants within a particular timeframe.
The main conclusion here is ... there's a limit to the amount of packet loss we can sustain, it's related to how many transactions we are trying to send (naturally, given the percent of failure is per packet.)
You can keep an eye on the runs of this action here: Network fault tolerance.
The main things to note are:
- Overall, the CI job will succeed even if every scenario fails. This is, ultimately, due to a bug in GitHub actions that prevents one from declaring an explicit pass-or-fail expectation per scenario. The impact is that you should manually check this job on each of your PRs.
- It's okay to see certain configurations fail, but it's certainly not expected to see them all fail; certainly not the zero-loss cases. Anything that looks suspcisious should be investigated.
Footnotes
-
This is not entirely true anymore as the
etcdbased implementation requires only a connection to the majority of the cluster. ↩